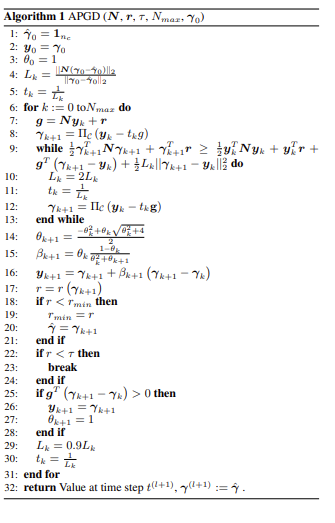梯度优化算法前世今生 (最后是APGD)
Author: Zhang Zijian
Introduction
APGD (Accelerated Projected Gradient Descent)
在介绍这个进阶算法之前,我们首先需要对其中最基础的算法GD做讲解,然后介绍动量,结合动量从而有Nertrov优化算法,最后结合投影进行优化。
Gradient Descent
梯度下降算法,是在神经网络,深度学习,计算机图形学,仿真等所有涉及到数值优化领域方向最基础的算法,我们从它入手,解开数值优化的神秘面纱。
什么是梯度?
在数学领域,有四个名词很像,分别是导数,偏导数,方向导数,梯度。
- 导数:导数可以表示函数曲线上的切线斜率。
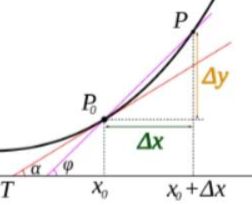
- 偏导数: 如果函数的维度上升,存在多变量的函数,那么就存在对不同变量求导这种情况,所以我们选择对其中一个变量求导,计算它的斜率,几何意义是表示固定面上一点的切线斜率。
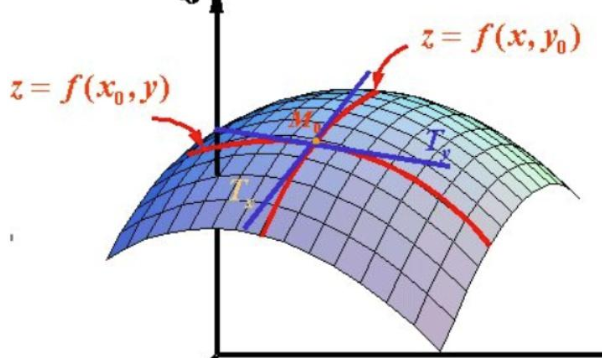
这个时候你是不是应该去问一个问题:我这个偏导数只能表示两个固定方向的斜率,x或y,但是对于一个平面上的一个点,他可能存在无数个方向上的切线,怎么去表示呢?
ok, 为了解决这个问题,数学家提出了一个概念叫方向导数。
- 方向导数:某个方向的导数,本质就是函数在A点上无数个切线的斜率的定义,每个切线都代表一个方向,每个方向都是有方向导数的。
举个例子来展示求解方式:
u=f(x,y) ,二元函数;
对于二元函数,求某点 $\left(x_{0}, y_{0}\right)$ 沿某方向 l 的方向导数: \(\begin{array}{c} \left.\frac{\partial f}{\partial l}\right|_{\left(x_{0}, y_{0}\right)}= f_{x}^{\prime}\left(x_{0}, y_{0}\right) \cos \alpha+f_{y}^{\prime}\left(x_{0}, y_{0}\right) \cos \beta \end{array}\) 其中:l 方向上单位向量是 $\vec{e_l}=\left(\cos \alpha ,\cos \beta \right),cos\alpha,cos\beta$ 是方向余弦。
最后,把所有方向函数这个标量收集起来,写成一个带方向的矢量,把方向导数这个线性算子编码起来,就是最重要的梯度!
- 梯度:梯度是一个矢量,在其方向上的方向导数最大,也就是函数在该点处沿着梯度的方向变化最快,变化率最大。
现在你是不是还应该有个问题?
为什么梯度告诉你“往哪走最快、能快到什么程度”?
why? Tell me Why?? 因为,任意方向的瞬时上升速度(方向导数)都等于梯度和该方向的点积;而点积在单位向量集合上的最大值
ok! 它的特性就可以被我们使用,在机器学习中逐步逼近、迭代求解最优化时,使用梯度,沿着梯度向量的方向是函数增加的最快,更容易找到函数的最大值,反过来,沿着梯度向量相反的地方,梯度减少的最快,更容易找到最小值。
什么是梯度下降?
举个常见的例子:你站在山上某处,想要尽快下山,于是决定走一步算一步,也就是每走到一个位置时,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走,这样一直走下去,很可能走不到山脚,而是某个局部的山峰最低处。(也就是我们说的陷入局部最优)。
梯度下降法就是沿着梯度下降的方向求解极小值,沿着梯度上升的方向可以求得最大值,这种方法叫梯度上升。
收敛终点是*梯度绝对小或者根据你自己设置,小于你的设定值。
那么什么情况才可以拜托局部最优呢?
这个与损失函数有关,当损失函数是凸函数的话,可以找到全局最优。
了解如下几个梯度下降相关的重要概念:(结合动力学仿真和机器学习一起讲)
- 步长(Learning rate / 迭代步长): 按照刚才的例子,步长就是你得到最佳的行走方向后,这步你走多大,很重要!我会在之后告诉你为什么重要。
不同的场景中步长的选择需要实验和权衡,步长越长,在陡峭区域下降的越快,但在平缓区容易出现反复抖动而找不到最优点;步长越短越不易产生抖动,但是容易陷入局部最优解。
如果不明白,我在具体的说一下:
当你选择步长太大,你可能走过了最佳点,然后再反向走回来,再走过去,出现抖动;
当你选择步长太小,可能走到一个山谷后走不出去,已经看作了最优解,出现了局部最优解的情况。
学习率(step size、迭代步长)本质上就是你在“这一步要走多远”。
- 假设函数(hypothesis function) :也就是我们要求解的目标函数。
梯度下降的例子:
最小化 \([ f(x_0,x_1)=x_0^2+50x_1^2 ]\)
它的梯度是
\[\nabla f(x)=\begin{bmatrix}2x_0\\100x_1\end{bmatrix}\]梯度下降更新公式
选择步长(学习率)($\alpha>0$),迭代 \(x^{k+1}=x^{k}-\alpha\,\nabla f(x^{k})\)
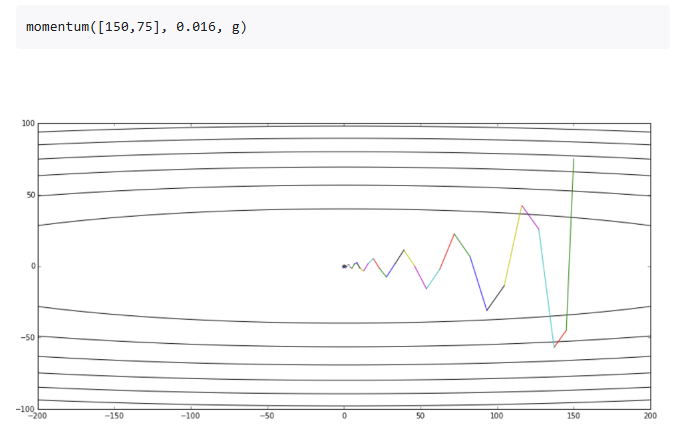
具体数值演示(从 ([150,75]) 出发,取 $(\alpha=0.01)$)
-
初始: $(x^{(0)}=(150,75))$ 函数值 \(f(x^{(0)})=150^2+50\cdot 75^2=22500+281250=303750\)
梯度 \(\nabla f(x^{(0)})=(300,\;7500)\)
一步更新 \(x^{(1)}=(147,\,0)\)
-
第 1 步后: 函数值 \(f(x^{(1)})=147^2=21609\)
梯度 \(\nabla f(x^{(1)})=(294,\,0)\)
再更新 \(x^{(2)}=(144.06,\,0)\)
-
第 2 步后: 函数值(只剩 (x_0) 方向在慢慢降) \(f(x^{(2)})=144.06^2\approx 20753.2836\)
你会发现:第一步把“陡峭”的 ($x_1$) 方向(权重 50)迅速拉到 0,随后在“平缓”的 ($x_0$) 方向上稳步减小,直到收敛到最小点 ((0,0))。
Momentum 动量
上面讲了关于梯度算法,我们发现它存在很多问题,第一就是收敛慢,第二是容易陷入局部最优解,所有在数学家聪明的大脑下,诞生了一种新的算法思路,借助物理上的动量的概念把之前的信息记录来加速求解。
什么是动量:我用我自己的理解来说,不一定准确,你把一个没有质量点,给予一个虚拟的质量,那么他在进行梯度下降的算法运动时,就会拥有动量的概念,从而可以记录之前的运动状态,因此一个已经完成的梯度+步长的组合不会立刻消失,只是会以一定的形式衰减,剩下的能量将继续发挥余热。
动量在“对的方向”叠加推进、在“错的方向”抵消抖动;
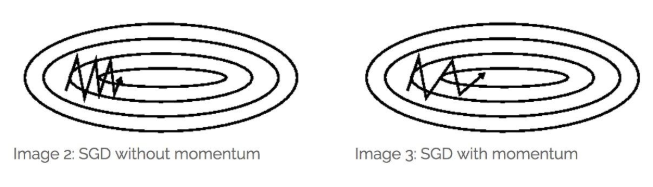
下面是博主提供的例子:
梯度下降:
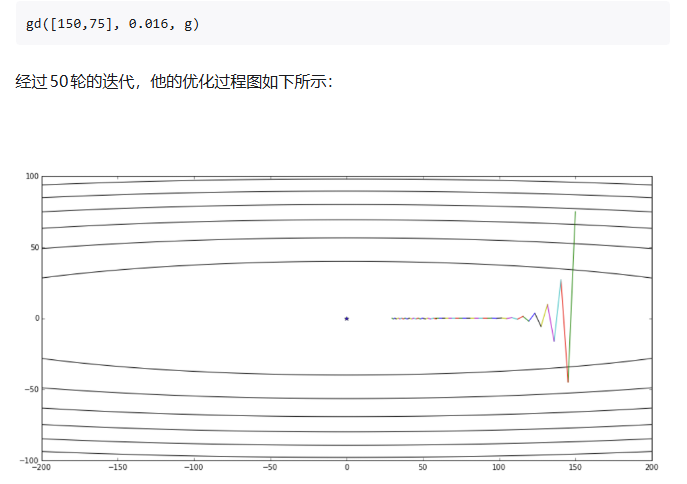
momentum
震荡明显偏少,但是还是存在不少问题,会让过冲冲的更猛。但是优势就是可以让收敛速度加快。
Nesterov Accelerated Gradient
这个算法,神奇就神奇在几乎没有改变动量算法,只做了一点点微小的工作,形式上发生了一点看似无关痛痒的改变,却能够显著地提高优化效果。
Momentum的想法很简单,就是多更新一部分上一次迭代的更新量,来平滑这一次迭代的梯度。
动量算法的公式: \(\begin{aligned} d_i &= \beta\, d_{i-1}+g(\theta_{i-1}),\\ \theta_i &= \theta_{i-1}-\alpha\, d_i \end{aligned}\)
我现在知道你每次迭代都会多走$\alpha\beta\, d_{i-1}$,那我为什么不先走怎么多,在这个中间点,再计算新的梯度去求解呢?为什么还要拿之前的梯度呢?ok,现在你已经领悟了Nestrov的精髓。
所以我们就能得出新的公式如下: \(d_i=\beta\, d_{i-1}+g\!\left(\theta_{i-1}-\alpha\beta\, d_{i-1}\right),\qquad \theta_i=\theta_{i-1}-\alpha\, d_i\) 所以你能看出,NAG和Momentum的区别就是在梯度更新的位置不同,它相当于内置了一个中间点,在这个中间点的位置计算新的梯度。
我们对公式进行一下推导:给出NAG的原始形式到等效形式的推导
原始形式: \(\begin{aligned} d_i &= \beta d_{i-1} + g\!\bigl(\theta_{i-1}-\alpha\beta d_{i-1}\bigr),\\ \theta_i &= \theta_{i-1}-\alpha d_i . \end{aligned}\)
可得:
\[\begin{aligned} \theta_i-\alpha\beta d_i &= \theta_{i-1}-\alpha(\beta+1)d_i \\[2pt] &= \theta_{i-1}-\alpha(\beta+1)\!\left[\beta d_{i-1}+g\!\bigl(\theta_{i-1}-\alpha\beta d_{i-1}\bigr)\right] \\[2pt] &= \theta_{i-1}-\alpha\beta d_{i-1}-\alpha\beta^2 d_{i-1}-\alpha(\beta+1)\,g\!\bigl(\theta_{i-1}-\alpha\beta d_{i-1}\bigr). \end{aligned}\]记: \(\boxed{ \begin{aligned} \hat{\theta}_i &\triangleq \theta_i-\alpha\beta d_i,\\ \hat{\theta}_{i-1} &\triangleq \theta_{i-1}-\alpha\beta d_{i-1},\\ \hat{d}_i &\triangleq \beta^2 d_{i-1}+(\beta+1)\,g(\hat{\theta}_{i-1}). \end{aligned}}\)
上式代入上上式,就得到了NAG等效形式的第二个式子:
\[\boxed{\ \hat{\theta}_i=\hat{\theta}_{i-1}-\alpha\,\hat{d}_i\ }.\]展开$\hat d_i$:
\[\begin{aligned} \hat d_i &= \beta^2 d_{i-1}+(\beta+1)g(\hat{\theta}_{i-1}) \\ &= (\beta+1)g(\hat{\theta}_{i-1})+\beta^2\!\left(\beta d_{i-2}+g(\hat{\theta}_{i-2})\right) \\ &= (\beta+1)g(\hat{\theta}_{i-1})+\beta^2 g(\hat{\theta}_{i-2})+\beta^3 d_{i-2} \\ &= (\beta+1)g(\hat{\theta}_{i-1})+\beta^2 g(\hat{\theta}_{i-2})+\beta^3\!\left(\beta d_{i-3}+g(\hat{\theta}_{i-3})\right) \\ &= (\beta+1)g(\hat{\theta}_{i-1})+\beta^2 g(\hat{\theta}_{i-2})+\beta^3 g(\hat{\theta}_{i-3})+\beta^4 d_{i-3}\\ &\ \ \vdots \\ &= (\beta+1)g(\hat{\theta}_{i-1})+\beta^2 g(\hat{\theta}_{i-2}) +\beta^3 g(\hat{\theta}_{i-3})+\beta^4 g(\hat{\theta}_{i-4})+\beta^5 g(\hat{\theta}_{i-5})+\cdots \end{aligned}\]于是我们可以写出$\hat d_{i-1}$的形式,然后用$\hat d_i$减去$\beta\hat d_{i-1}$消去后面的无穷多项,就得到了NAG等效形式的第一个式子:
\[\beta\hat d_{i-1} = \beta(\beta+1)g(\hat{\theta}_{i-2})+\beta^3 g(\hat{\theta}_{i-3}) +\beta^4 g(\hat{\theta}_{i-4})+\beta^5 g(\hat{\theta}_{i-5})+\cdots\] \[\begin{aligned} \hat d_i-\beta\hat d_{i-1} &= (\beta+1)g(\hat{\theta}_{i-1})-\beta g(\hat{\theta}_{i-2}) \\ &= g(\hat{\theta}_{i-1})+\beta\!\left[g(\hat{\theta}_{i-1})-g(\hat{\theta}_{i-2})\right]. \end{aligned}\]这个NAG的等效形式与Momentum的区别在于,本次更新方向多加了一个$\beta!\left[g(\hat{\theta}{i-1})-g(\hat{\theta}{i-2})\right]$, 它的直观含义就很明显了:如果这次的梯度比上次的梯度变大了,那么有理由相信它会继续变大下去,那我就把预计要增大的部分提前加进来;如果相比上次变小了,也是类似的情况。
这个就是用梯度近似的二阶导的信息(利用了一阶梯度的变化量即二阶导数。),所以NAG本质上是多考虑了目标函数的二阶导信息,怪不得可以加速收敛了!其实所谓“往前看”的说法,在牛顿法这样的二阶方法中也是经常提到的,比喻起来是说“往前看”,数学本质上则是利用了目标函数的二阶导信息。
APGD
基于Nestrov我们可以进一步的应用到我们的多体动力学仿真上,也就是把摩擦锥加进去。
我们对于Nestrov的知识,已经知道他会在每次迭代走一个固定的距离,然后在所谓的中间点更新一次进度,所以我们把公式换一种形式展示:
\[\begin{alignat}{1} & x_{k+1} = y_k - t_k \nabla f(y_k) \tag{16}\\ & \theta_{k+1}\ \text{solves }\ \theta_{k+1}^2 = (1-\theta_{k+1})\,\theta_k^2 + q\,\theta_{k+1} \tag{17}\\ & \beta_{k+1} = \frac{\theta_k(1-\theta_k)}{\theta_k^2+\theta_{k+1}} \tag{18}\\ & y_{k+1} = x_{k+1} + \beta_{k+1}\big(x_{k+1}-x_k\big) \tag{19} \end{alignat}\]- $f:\mathbb{R}^n!\to\mathbb{R}$:目标函数,凸且梯度 Lipschitz 连续。 $|\nabla f(x)-\nabla f(y)|\le L|x-y| \quad(\text{定义 }L)$
- $x_k$:第 (k) 次迭代的当前点(主变量)。
- $y_k$:第 (k) 次迭代的外推/加速点(用来算梯度与下一步)。
-
$t_k>0$:步长(学习率)。常见两种设定:
- 固定步长 $t_k=\tfrac{1}{L}$(已知 (L) 时);
- Armijo 回溯/非单调线搜索(未知 (L) 或追求更稳)。
- $\theta_k\in(0,1]$:动量刻度参数。它通过 (17) 与强凸性比值 (q) 耦合,决定外推“拉多远”。
- $\beta_{k+1}$:由 $\theta_k,\theta_{k+1}$ 计算的外推系数,用于形成 $y_{k+1}$(见 (18)–(19))。
-
$q\in[0,1)$:强凸性比值,定义为 $ \boxed{q=\mu/L,} $ 其中 $\mu$ 是 $f$ 的强凸常数(若 $f$ 满足 $f(x)\ge f(x^\star)+\tfrac{\mu}{2}|x-x^\star|^2)$。
- 强凸情形:已知 $\mu>0$ 时用 $q=\mu/L$;
- 一般凸情形:$\mu$ 不知或为 0,取 (q=0),这就是经典的 Nesterov/FISTA,加速率 (O(1/k^2))。
- $\nabla f(y_k)$:在加速点的梯度;(16) 用它做一次普通的梯度前进;(18)–(19) 再把这步“拉长”以实现加速。
现在我们已经得到了相关的公式,但是其中的强凸性比值被设定为0,虽然根据之前建模的部分,我们已经把求解方程变成了一个QP问题: \(\min_{\lambda \in \mathcal{K}} \quad f(\lambda) = \frac{1}{2} \lambda^T Z \lambda + \lambda^T d\)
但是如$A$正定,$f$就是强凸,理论上可以用 $q=\mu/L$但在多体约束里,“强凸”往往拿不到,或拿到也不稳定,所以工程上普遍仍取$𝑞=0$。但是$A$只保证半正定(PSD),不是必然正定。 \(\begin{align} x_{k+1} &= \Pi_{\mathcal K}\!\big( y_k - t_k \nabla f(y_k) \big) \tag{20}\\ \theta_{k+1}\ \text{solves}\quad \theta_{k+1}^2 &= (1-\theta_{k+1})\,\theta_k^2 \tag{21}\\ \beta_{k+1} &= \frac{\theta_k(1-\theta_k)}{\theta_k^2+\theta_{k+1}} \tag{22}\\ y_{k+1} &= x_{k+1} + \beta_{k+1}\big(x_{k+1}-x_k\big) \tag{23} \end{align}\)
当我们搞懂Nestrov之后,我们最优把算出的值投影到摩擦锥,说人话,就是给计算值加一个限制,只不过这个摩擦锥我们需要用到数学化表达,——这个可行域由盒约束(上下界)和摩擦锥(这部分在代码中所有体现即可)。
现在我们的算法的原理讲完了,我们加一些工程方面的优化:
-
Matrix Free 机制
建模阶段是通过对不同块的矩阵进行偏移,也就是编码,然后不组装大矩阵Z,看求解器需要不,如果是直接线性求解器,类比VEROSIM中的dantzig,那么我就按照编号把大矩阵组装好,然后进行线性的求解,但是对于APGD这种迭代的求解器暂时不需要大矩阵,那么他在APGD调用相关数据时,比如N和R时,就可以根据偏移编码,读取出数据,从而进行计算,怎么编写的目的是为“既能装配、也能算子式”的通用接口层,方便不同类型求解器插拔。
-
迭代步长自适应/学习率自适应
这里引入一个知识点,用“二次上界”做合格证。FISTA 的回溯线搜索(backtracking line-search),常把它口头叫“Lipschitz 回溯”(Lipschitz backtracking) \(f(\mathbf{x}) \;\le\; f(\mathbf{y}) \;+\; \nabla f(\mathbf{y})^{\!\top}(\mathbf{x}-\mathbf{y}) \;+\; \frac{L}{2}\,\lVert \mathbf{x}-\mathbf{y} \rVert^2 .\)
这段“二次上界当作合格证”的逻辑,核心是下降引理(descent lemma):只要目标的梯度在局部是 $L$-Lipschitz(即“变化不太猛”),那么 $f$ 在任意点 $\mathbf{y}$ 的一阶泰勒近似再加一个二次项,就能上界住 $f$ 在任意点 $\mathbf{x}$ 的值。把这个上界当作“合格证”,就能做回溯线搜索:若用当前 $L_k$ 构造的二次上界已经比真实的 $f(\mathbf{x}_{k+1})$ 高,那这次步长 $t_k=1/L_k$ 就是安全的;否则把 $L_k$放大一点再试,直到安全为止。
% — FISTA/Lipschitz 回溯判据(式(24))— \(f(\mathbf{x}_{k+1}) \;\le\; f(\mathbf{y}_k) \;+\; \nabla f(\mathbf{y}_k)^{\!\top}(\mathbf{x}_{k+1}-\mathbf{y}_k) \;+\; \frac{L_k}{2}\,\bigl\lVert \mathbf{x}_{k+1}-\mathbf{y}_k \bigr\rVert^2 .\)
已经在论文A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems 证明。
所以根据这个下降引理,我们可以让步长变得更加的合理,当不满足下降引理时,说明步长太大,需要增大$L$的值来减小步长,所以我们使用$L=2L$,
然后在本次迭代结束前,适当的缩小$L$的值来增加步长,可以适当的加速。 $L_{k+1} = 0.9\,L_k$,这样让收敛速度更快。
$L_0$的初始化值为: \(L_0 \;=\; \frac{\left\lVert \nabla f(\mathbf{z}_0) - \nabla f(\mathbf{z}_1) \right\rVert} {\left\lVert \mathbf{z}_0 - \mathbf{z}_1 \right\rVert}, \qquad \mathbf{z}_0 \neq \mathbf{z}_1 .\) 见于 FISTA/backtracking 文献与 APGD 论文注释
-
自适应重启
全称是:Nesterov 动量的“自适应重启(Adaptive Restart),当动量方向“顶着”负梯度(也就是要往上爬 hill)时,干脆把动量清零,避免来回振荡,恢复稳定下降。这段在说 Nesterov 动量的“自适应重启(Adaptive Restart)”:当动量方向“顶着”负梯度(也就是要往上爬 hill)时,干脆把动量清零,避免来回振荡,恢复稳定下降。
核心判据:当 $\big\langle \nabla f(y_{k-1}), x_k - x_{k-1}\big\rangle > 0$ 就立即重启:把动量置零$(\theta_k=1)$,并令$y_k = x_k$
含义:$(x_k-x_{k-1})$ 是“上一步的位移/动量方向”。若它与当前梯度 $\nabla f(y_{k-1})$ 夹角小于 $90^\circ$(内积为正),说明动量方向与负梯度相反(即与最速下降方向“唱反调”)。此时继续用动量会“涟漪”甚至反弹,于是重启。
-
Fallback
这个就是回退机制,也就是全文中比较重要的机制,像 APGD 这种非单调迭代法,迭代中和结束时的当前解 $x_k$ 不一定是这一路里“最好”的那个。为保证输出的单调性(至少别比历史最好还差),就在退出时把历史上最好的一次迭代拿出来当作最终解。 所以需要有best的记录功能。
Overall of APGD
综合上面所有的推导,最后的伪代码如下: